
This blog is written by three PhD students in mathematics and the mathematical posts are categorized by the level of technical knowledge required to appreciate them fully: Posts in the “For Everyone” category assume no knowledge of mathematics beyond that which it is compulsory to study at school. The posts in the “For Mathematicians” category contain or are about advanced mathematics studied at graduate level and beyond. The “For Students” category is for everything in between.
Introduction
In this post we will be looking at probabilistic coupling, which is putting two random variables (or proceses) on the same probability space. This turns out to be a surprisingly powerful tool in probability and this post will hopefully brainwash you into agreeing with me.
Consider first this baby problem. You and I flip coins and 


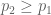

be the first times 
![\mathbb{E}[T_X]\leq \mathbb{E}[T_Y]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BT_X%5D%5Cleq+%5Cmathbb%7BE%7D%5BT_Y%5D&bg=ffffff&fg=545454&s=0&c=20201002)
Of course here it is possible to compute both of the expectations and show this directly, but this is rather messy and long. Instead this will serve as a baby example of coupling.
In the previous post we discussed the number of primes less than a given number and derived some very poor estimates for this quantity. In this post, using no extra technical machinery whatsoever, we derive a slightly better estimate.
Previously, we used Euclid’s proof of the infinitude of the primes as inspiration for a way of arriving at an upper bound for the number of primes less than a given number. Here, we will come up with a slightly cleverer, more quantitative proof of Euclid’s Theorem and, as before, our estimate will grow out of the proof of Euclid’s Theorem, the improvement in the bound being testament to the fact that the proof is more illuminating.
If we are prepared to accept that every number greater than one has a prime divisor, then Euclid’s famous proof of the infinitude of prime numbers is one sentence long: Given any prime number p, if I multiply together all the prime numbers less than or equal to p and then add one, I get a number which leaves a remainder of one when divided by any of the prime numbers less than or equal to p and whence has a prime divisor greater than p. I try to explain why every number greater than one has a prime divisor in this post.
Today I would like to think a little bit more about prime numbers. Specifically, we will spend some time thinking about the number of prime numbers less than a given a number. We will start by seeing if we can get any quantitative information out of Euclid’s proof itself, before moving on to cleverer ways of achieving this.
The study of whole numbers is one of the oldest lines of inquiry in mathematics which is still thriving today. After all, it is possible in pure mathematics for the relevance of work done thousands of years ago to be undiminished today. I want to talk today about what is possibly the prototypical example of such a piece of mathematics. I am referring to Euclid’s proof of the infinitude of prime numbers.
A divisor of a number n is another, smaller number, for which there is no remainder when n is divided by it. For example, three is a divisor of six, seven is a divisor of seven and thirty-nine is a divisor of one hundred and seventeen. A prime number is a number with exactly two divisors. Let’s think about what it means to have exactly two divisors. Firstly, we observe that every whole number has at least one divisor, namely the number itself. Secondly, every whole number except for ‘1’ has at least two divisors: The number itself and the number ‘1’. So, with the exception of the number ‘1’, being prime expresses the quality of having the fewest possible divisors. Why must there must be infinitely many such numbers?
Ever wonder what happens when you send your card details over the internet? How exactly does public-key encryption work? I will write a brief, non-technical introduction to these concepts and the mathematical background in them, containing some sample code and plenty of examples.
Before we describe the RSA algorithm, there is one important mathematical concept, which is prime numbers and their factorization. Recall that a number 


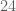

There is a fundamental theorem in number theory which says that every number 




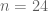
At this point now I can state what is the fundamental idea behind RSA:
Factoring a number into prime factors is much harder than checking if a number is prime!
But why is this true? There are technical reasons for this but I prefer to think along the following lines. Computers are much like humans, so imagine if a human is given the task of factorising numbers and checking if numbers are prime.
The trolley dilemma is summed in two parts as follows. Suppose that a trolley is running down a hill at a fast speed, heading towards five people at the bottom of the street. When it reaches them it will surely kill all of them. You notice that there is a switch next to you that could direct the trolley to a side path where there is one man standing and once you do, it will be the one man that dies. Would you do it?

Most people would answer this question with an affirmative. Let us call this the switch scenario. The second scenario is that a trolley is again running down a hill at fast speed, aimed at five people at the bottom which it will surely kill. However this time you are standing on a bridge with a fat man next to you. If you push the fat man off the bridge the trolley will stop but kill that fat man. Would you do it?
Read the rest of this entry »
This post will be essentially about functions of bounded variation of one variable. The main source is the book “Functions of Bounded variation and Free Discontinuity Problems” by Ambrosio, Fusco and Pallara. Before we give the definition of a bounded variation function let us recall what exactly does is mean for a function to belong in 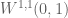




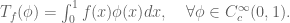
In that case we say that the distribution 


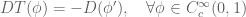
In the special case where the distribution 
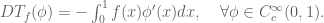
If you haven’t read my previous post, I would suggest doing so before this. We denote by 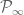

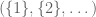
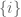

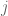


With this in mind, define the operator 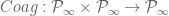
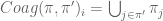
With some conditions, we can define the same operator on ![\mathcal{P}_{[n]}](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BP%7D_%7B%5Bn%5D%7D&bg=ffffff&fg=545454&s=0&c=20201002)
![[n]:=\{1,\dots,n\}](https://s0.wp.com/latex.php?latex=%5Bn%5D%3A%3D%5C%7B1%2C%5Cdots%2Cn%5C%7D&bg=ffffff&fg=545454&s=0&c=20201002)

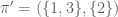

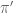
Let’s jump straight in. Suppose I have a collection of n different objects, where n is some unknown but fixed whole number. Suppose I want to arrange k of them in a row on my shelf, where k is some unknown but fixed whole number less than or equal to n. In how many ways can this be done?
This is a counting problem. You are being asked to count how many of something there are. The answer will be a formula involving the unknown quantities n and k. Counting is often thought of as being easy. While it is true that the things which must be counted are easy to describe (I have just done so in a couple of sentences), this does not mean that the problem of counting them is easy. So, in this post I continue my quest to explain some basic things about counting and how to do it.
